



注意:本文不介绍如何使用Qt的国际化、本地化支持。本文针对的是偏底层的、Manual和其他资料中很少涉及的东西。所以,继续之前,请先确保:你已经对如何使用Qt的国际化比较熟悉了。
本文针对的是 tr("我是中文") 这种情况。
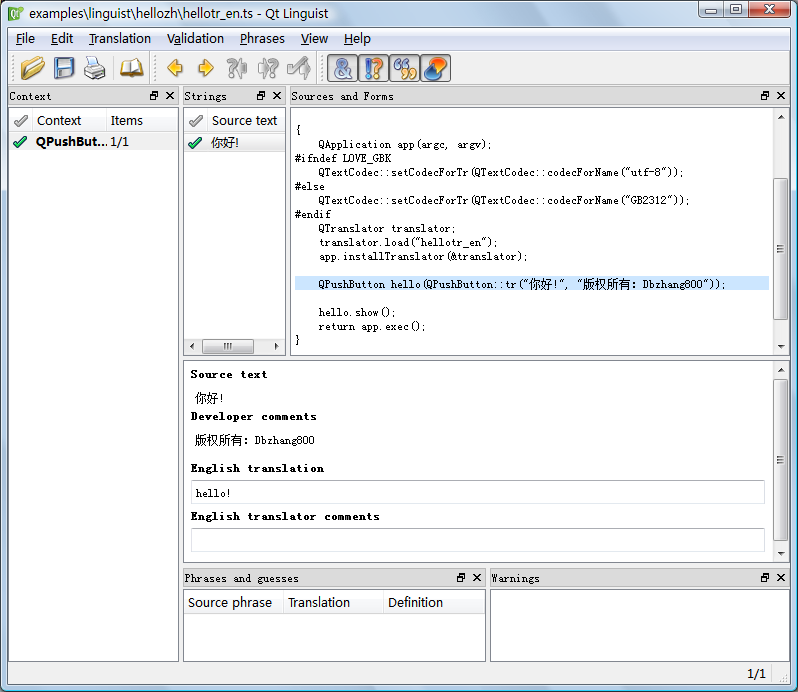
例子
首先,个人比较抵制源码中使用中文(当然也包括用tr扩住中文了)。但是如果非要用,也不是不可以。之前也提到了这个问题。
废话少说,看个例子:
#include <QApplication>
#include <QPushButton>
#include <QTextCodec>
#include <QTranslator>
int main(int argc, char *argv[])
{
QApplication app(argc, argv);
#ifndef LOVE_GBK
QTextCodec::setCodecForTr(QTextCodec::codecForName("utf-8"));
#else
QTextCodec::setCodecForTr(QTextCodec::codecForName("GB2312"));
#endif
QTranslator translator;
translator.load("hellotr_en");
app.installTranslator(&translator);
QPushButton hello(QPushButton::tr("你好!", "版权所有:Dbzhang800"));
hello.show();
return app.exec();
}
大家应该都知道如何做了:
-
使用lupdate 生成 hellotr_en.ts 文件
-
使用linguist 打开该文件进行翻译
-
使用lrelease (或通过linguist的菜单)将其转换成hellotr_en.qm文件
三步走下来,结果正常,界面能显示翻译出来的问题。但是,翻译过程中有一点会很不爽:
- hellotr_en.ts 文件中,本该显示"你好!"的地方出现的是一堆乱码!
- 当然,使用linguist进行翻译时很难受,因为你不知道乱码处是什么东西
为了解决这个问题,我们不妨从源头lupdate开始看看。
lupdate
作用:从源码文件中提取待翻译的字符串
目前支持的源码文件的后缀:
java,jui,ui,c,c++,cc,cpp,cxx,ch,h,h++,hh,hpp,hxx,js,qs,qml
我们这儿只关心与C++有关的源码文件(QtJambi、QtScript、!Qt Quick相关的源码文件可能会有不同,我不能确定),能力和精力有限哈。
生成.ts文件
要使用lupdate,细分一下,有两种方式:
- 在 .pro 中指定要生成的ts文件:
TRANSLATIONS = hello_zh_CN.ts hello_zh_TW.ts
- 在命令行中指定要生成的ts文件(这时将忽略.pro内指定的文件):
lupdate hello.pro -ts hello_zh_CN.ts hello_zh_TW.ts
乱码?
我们已经充分见识了源码中包含非latin1字符时的编码问题。 lupdate 要从源码文件中提取中文字符串,但它无从知道那我们使用的utf-8,还是gbk,又或者是big5等等编码。所以,需要我们告诉它!
前面提到lupdate的两种用法,那么我们要分别通过两种方法告诉它我们的文件是何种编码:
- 在 .pro 中指定要生成的ts文件时,在 .pro 文件内指定编码
CODECFORTR = utf-8 #or gbk #DEFAULTCODEC = utf-8 #CODEC = utf-8
注意,如果 CODECFORTR 没有定义,将找 DEFAULTCODEC,如果还没有定义,将找 CODEC。3个都没有定义的话,就采用latin1
- 在 命令行指定 ts 文件时,需要在命令行指定编码
lupdate hello.pro -codecfortr utf-8 -ts hello_zh_CN.ts hello_zh_TW.ts
-
万恶的MSVC?
- 注意:如果你在使用msvc的编译器,除了前面提到的东西,你还需要知道一点:
- 如果你的源码文件是带BOM的utf8,utf16等编码格式,它会有转码的动作。
- 这样一来,tr()包住的字符串将转码成时GBK、BIG5等system编码,与源文件所用的编码不同。
- 所以,对此,我们还需要指定源文件的编码:
CODECFORTR = GB2312 CODECFORSRC = UTF-8
恩,编码设置挺顺利的,这样一来,lupdate根据指定的编码能识别我们的汉字,然后生成的.ts文件不再是乱码了,同时,它在.ts文件中记录下源码中窄字符串的编码
<defaultcodec>GB2312</defaultcodec>
-
注意 :lupdate 存在一些bug,你如此操作之后,程序运行时可能会无法加载翻译的内容!!我们稍后介绍。
lrelease
lrelease 是 Linguist 工具链的一部分,可作为独立程序使用。它将 .ts 文件转换成压缩的 .qm 文件,供 QTranslator 使用。
- 读入.ts 文件(.ts文件是包含编码信息的xml文件,不存在乱码的基础)
-
将读入的字符串编码 后按某种格式存储后 .qm 文件中
- 默认情况下,采用latin1编码
- 对于.ts文件中包括defaultcodec的,采用该编码
对应于前面 lupdate 的用法,lrelease也有两种用法
- pro 文件内指定了 ts 文件
lrelease project.pro
- 通过命令行指定 ts 文件
lrelease ts-files [-qm qm-file]
注意bug!
我们刚才提到 .ts 到 .qm 的过程,存在一个编码的过程。具体到我们前面提到的GB2312,意味着lrelease需要使用Qt的插件(比如qcncodecs4.dll)。
但很不幸,当前版本(Qt4.7)的lrelease存在bug。
- 我不知道Qt在搞什么飞机,它程序中没有使用QCoreApplication(反而做了很多其他的工作),结果导致无法加载插件。这样一来,QString 中存放的unicode字符串将强制转成latin1(信息丢失!)
注意:如果你使用的utf-8编码,则不存在这个问题。因为utf-8不需要插件。
如何避免?
尝试阅读lrelease的源码,因为功底太差,最终放弃。所以我也无法提供补丁,只告诉大家一个折中的方法:
如果你在简体中文的windows系统中使用gb2312,那么在指定编码是,直接指定SYSTEM而不要指定GB2312 ,这样一来,可以避免使用codecs插件。
这样的话,.ts中的字符串将会在不借助codecs插件的情况下被lrelease成功地被转码成gb2312。我们的程序此时又可以成功加载翻译了。鼓掌!呵呵
lingiust
- 通过设置字符集,我们在lingiust中进行翻译时,已经可以正常看到汉字了
- 因为它是从.ts文件加载的,xml格式的.ts文件是不存在乱码基础的
- 但是一点例外:就是 lingiust 显示源码的窗口(Sources and Forms)中,汉字依然是乱码
原因?
个人认为这应当是lingiust的一个bug。
- 因为它显示源码时,简单粗暴,直接按照latin1进行读入的
- 实际上,.ts 文件中已经包含 defaultcodec 信息了,但是它却没有使用。
怎么办?我想应该这样来做(其实lupdate也应该这样来做的,如果这样做了,就不用对MSVC的情况单独设置一个source编码了)。
- 如果源码文件包含BOM信息,则直接按照BOM提供的编码信息读入源文件。
- 如果不包含BOM,则按照.ts文件指定的编码读入读入源文件
折中之道
如果你只是想让lingiust能正确显示编码,那么你只需要找到:
-
文件%QTDIR%/tools/linguist/linguist/sourcecodeview.cpp
找到:
void SourceCodeView::showSourceCode(const QString &absFileName, const int lineNum)
{
...
fileText = QString::fromLatin1(file.readAll());
...
}
改为
QString::fromLocal8Bit
重新编译一下lingiust即可。
至此,我们的任务完成!
小结
总结一下:
-
运行lupdate从源码中提取待翻译字符串,需要指定待翻译串的编码 (注意msvc对带BOM文件的处理)
- 运行linguist进行翻译(如果让源码窗口显示也正常,需修改至少一行代码)
- 运行lrelease将.ts编程qm文件,这时对gb2312的处理存在问题,我们采取一个补救措施
作者:dbzhang800



